A software engineer has discovered an innovative method to hide data within emoji and other Unicode characters, raising both technical intrigue and security concerns across the tech community.
Paul Butler detailed the technique in a recent blog post, demonstrating how Unicode's "variation selectors" - special code elements that typically modify character appearance - can be repurposed to embed secret information within seemingly innocent text.
The method takes advantage of how Unicode represents characters internally. While most Western letters map directly to single codes, Unicode includes 256 special "variation selector" codes that don't create visible changes but must be preserved when text is processed. Butler realized these invisible codes could encode data bytes within any Unicode character, including popular emoji.
"This preservation requirement creates an opportunity to hide information," Butler explained in his post. "A single character can carry multiple bytes of hidden data through these variation selectors, with no visible indication anything is unusual."
The implications extend beyond mere technical curiosity. Security experts warn this technique could enable bad actors to bypass content moderation systems, as the hidden data becomes invisible once displayed. The method could also enable sophisticated tracking - organizations could uniquely watermark messages sent to different recipients, potentially compromising whistleblower anonymity.
Butler's experiments with AI language models revealed another dimension: while most models preserve these special codes during processing, they generally avoid interpreting the hidden data. However, when paired with code interpreters, some advanced AI systems can detect and decode the concealed information.
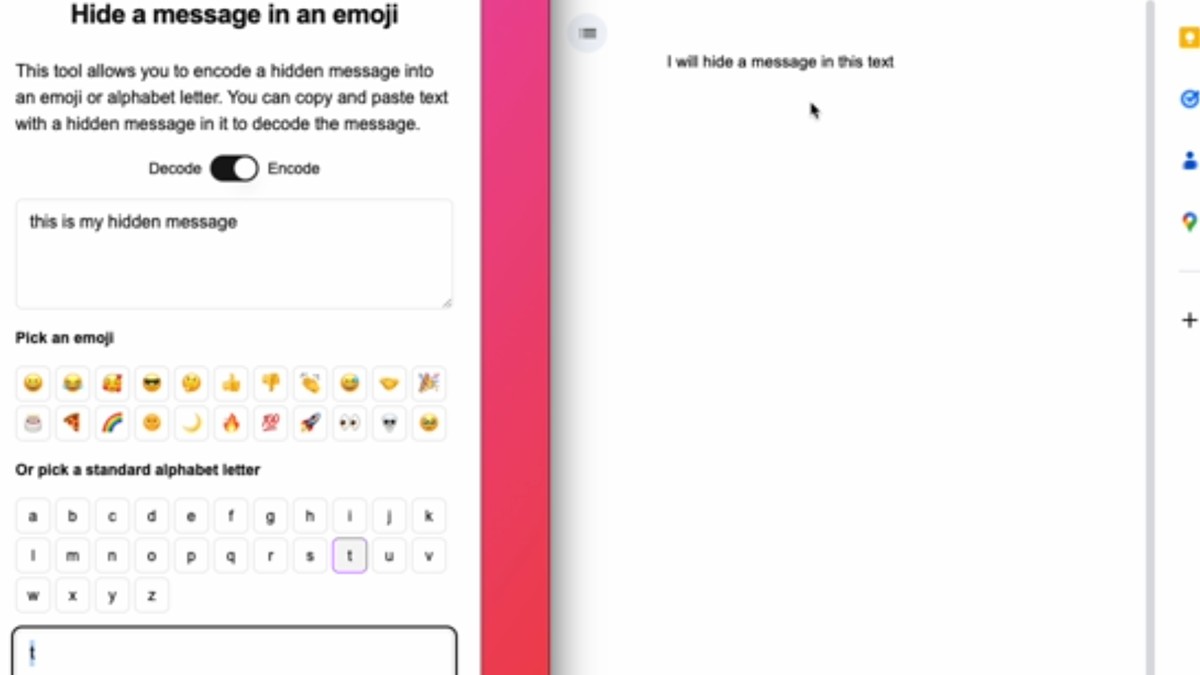
To demonstrate the concept, Butler released an online tool allowing users to experiment with encoding and decoding hidden messages within emoji. The tool transforms regular text into specially crafted Unicode characters that appear normal but contain embedded data recoverable using Butler's decoder.
As this technique gains attention, it highlights the ongoing challenge of balancing Unicode's flexibility with potential security risks. While innovative, such methods may require new approaches to content filtering and digital forensics to prevent misuse.