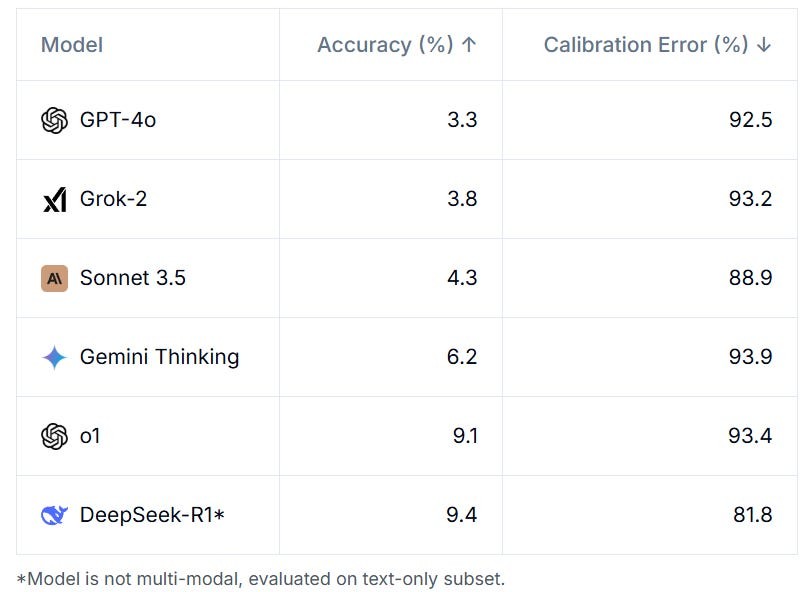
The Center for AI Safety (CAIS) and Scale AI have released findings from an ambitious new AI benchmark designed to test the boundaries of artificial intelligence systems. The test results reveal that even the most advanced AI models currently struggle with expert-level reasoning, correctly answering less than 10% of the challenging questions.
Named "Humanity's Last Exam," the benchmark evaluated AI systems' capabilities across mathematics, humanities, and natural sciences through a carefully curated set of complex problems. The project emerged as a response to "benchmark saturation" - where AI models achieve near-perfect scores on existing tests but may falter with novel challenges.
The extensive evaluation process involved collecting over 70,000 trial questions, which were narrowed down to 13,000 for expert review, ultimately resulting in 3,000 final questions. Leading AI models tested included OpenAI's GPT-4o, Anthropic's Claude 3.5 Sonnet, Google's Gemini 1.5 Pro, and OpenAI's o1.
The project brought together nearly 1,000 contributors from more than 500 institutions across 50 countries, primarily comprising active researchers and professors. Questions spanned both text-only and multi-modal formats incorporating images and diagrams.
"We wanted problems that would test the capabilities of the models at the frontier of human knowledge and reasoning," explained Dan Hendrycks, CAIS co-founder and executive director. He noted how rapidly AI capabilities can advance, referencing how the MATH benchmark scores jumped from below 10% to over 90% in just three years.
The benchmark included highly specialized questions across various fields. For instance, one ecology question delved into the intricate anatomy of hummingbird bone structure and associated tendons.
To encourage high-quality contributions, the organizers offered substantial financial incentives - $5,000 for each of the top 50 questions and $500 for the next 500 best submissions. Contributors also received the opportunity for coauthorship of the final paper.
CAIS and Scale AI plan to make the dataset available to the research community while retaining a small subset of questions for future evaluations. This release will enable deeper analysis of model variations and continued assessment of AI system limitations.