
Federal Judge Advances New York Times' Copyright Lawsuit Against OpenAI
A landmark lawsuit by The New York Times against OpenAI and Microsoft over AI training data copyright infringement will proceed after a federal judge's ruling. The case, centered on unauthorized use of news articles to train ChatGPT, could set crucial precedents for AI companies' use of copyrighted content.

OpenAI's Ghibli-Style AI Art Sparks Copyright and Ethics Debate
OpenAI's new image generation feature allowing Ghibli-style creations triggered both excitement and backlash from the creative community. The controversy escalated when users began generating inappropriate historical imagery, leading to restrictions and renewed discussions about AI's impact on artistic rights.

OpenAI Cracks Down on Chinese Surveillance Operations Using ChatGPT
OpenAI has banned Chinese accounts that exploited ChatGPT for surveillance and disinformation campaigns targeting Western countries and Latin America. The company identified two malicious operations, 'Peer Review' and 'Sponsored Discontent', which aimed to monitor protests and spread anti-American content.

AI's Growing Dominance Revives 'Dead Internet' Fears
As AI-generated content floods social platforms, the Dead Internet Theory suggesting most online activity is artificial gains new relevance. Researchers warn of an expanding synthetic ecosystem where AI agents dominate content creation and engagement, raising concerns about authentic human connection.
OpenAI Unveils O3-Mini: A Faster, Cost-Effective AI Model for Technical Computing
OpenAI's latest language model O3-Mini delivers enhanced capabilities in science, mathematics, and coding while offering faster response times and lower costs. Now available through ChatGPT and developer APIs, the model demonstrates impressive performance on technical challenges while maintaining robust safety measures.

Digital Resistance: Developers Deploy AI Traps to Combat Aggressive Web Scrapers
Frustrated developers are fighting back against unauthorized AI web crawlers by creating digital 'tarpits' designed to trap and contaminate AI training data. The movement gained momentum after accusations of aggressive scraping by major AI companies, with tools like Nepenthes and Iocaine emerging as symbols of resistance.

Chinese AI Startup DeepSeek Halts New Registrations After Major Cyberattack
DeepSeek, a rising Chinese AI company that recently surpassed ChatGPT in App Store downloads, faces service disruption from large-scale attacks. The startup's cost-effective approach and recent R1 model launch have positioned it as a formidable competitor to established AI leaders.

AI Researchers Face Mental Health Crisis Amid Relentless Industry Pressure
The AI industry's breakneck pace is taking a severe toll on researchers' wellbeing, with many reporting 100+ hour work weeks and deteriorating mental health. Despite lucrative positions at major tech companies, the intense competition and pressure to deliver results is creating an unsustainable work environment.

The Dangerous Deception: How AI Companies' AGI Claims Put Lives at Risk
As tech giants promise artificial general intelligence (AGI) while concealing deadly failures, evidence mounts that human-level AI may be impossible. With trillion-dollar costs and growing casualties, experts warn the industry must shift from AGI pursuit to augmenting human capabilities.
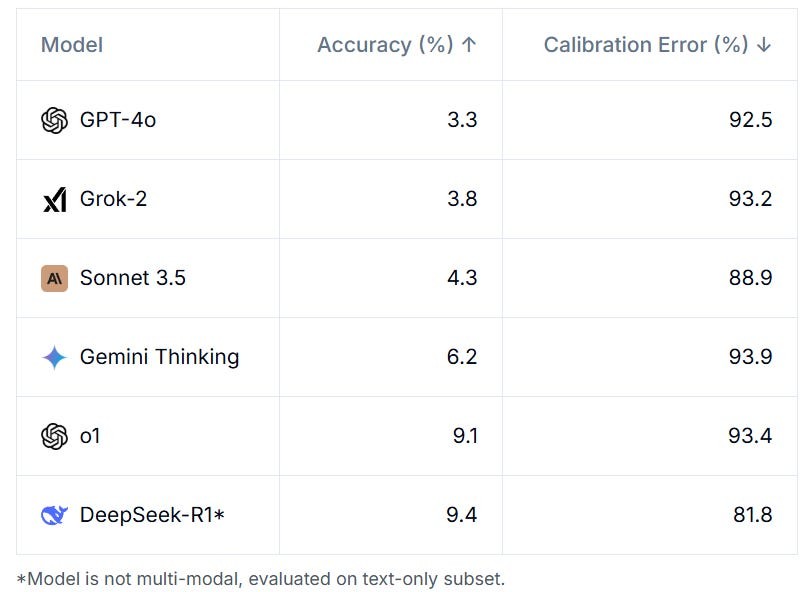
AI Models Score Below 10% on Groundbreaking 'Humanity's Last Exam' Benchmark
Leading AI systems, including GPT-4 and Claude 3.5, struggled with expert-level reasoning in a comprehensive new benchmark spanning mathematics, humanities, and sciences. The ambitious project, developed by CAIS and Scale AI, involved nearly 1,000 contributors from 500 institutions creating challenging questions to test AI capabilities.